Automating machine learning with a joint selection framework
Authors
Authors
- Sijia Liu
- Parikshit Ram
- Deepak Vijaykeerthy
- Djallel Bouneffouf
- Gregory Bramble
- Horst Samulowitz
- Dakuo Wang
- Andrew Conn
- Alexander Gray


Authors
- Sijia Liu
- Parikshit Ram
- Deepak Vijaykeerthy
- Djallel Bouneffouf
- Gregory Bramble
- Horst Samulowitz
- Dakuo Wang
- Andrew Conn
- Alexander Gray
Published on
02/12/2020
Categories
Artificial intelligence has proven difficult for organizations to implement in real-world settings. Automated machine learning (AutoML) is one way we can make AI more widely accessible. In a new research paper presented at the 2020 AAAI Conference, entitled, An ADMM Based Framework for AutoML Pipeline Configuration, we explore the Automated Machine Learning (AutoML) problem of automatically configuring machine learning pipelines by jointly selecting machine learning algorithms and their appropriate hyper-parameters.
Toward AutoML
AutoML can allow non-ML experts to build and use machine learning systems for handling targeted tasks without the need of domain knowledge. For example, biologists and doctors (who are not ML experts) can use AutoML toolbox to build the suitable ML system to analyze complex biological and medical data.
Using AutoML, one could build machine learning pipelines from raw data directly, without needing to write complex code and or perform tedious tuning and optimization, to then automate complicated, labor-intensive tasks.
However, the application of AutoML in real world problems requires the automation process to be fast. In our research, we aim to improve the efficiency of AutoML. Real-world data science problems are not limited to the optimization of a single (abstract) objective. In the data science process, there are many different stakeholders with different constraints, such as DevOps having deployment constraints or regulators having fairness constraints.
An ADMM-based approach for AutoML
The alternating direction method of multipliers (ADMM) is an algorithm that solves convex optimization problems by breaking them into smaller pieces, each of which are then easier to handle. It has wide applications. For the purposes of AutoML, we have designed an ADMM-based framework securing securing several advantages:
- It is able to decompose the high-dimension complex AutoML problem into easily-solved and low-dimension sub-problems (demonstrating over 10× speedup and 10% improvement in many cases).
- It is also able to incorporate user-customized (black-box) utility constraints along-side the (black-box) ML pipeline optimization objective. This Auto ML problem is challenging, because the explicit expressions of objectives and constraints are intractable, and thus we call the black-box nature of the problem.
- We demonstrate the effectiveness of the ADMM-based scheme empirically against popular AutoML toolkits Auto-sklearn (Feurer et al. 2015) & TPOT (Olson and Moore 2016) (Section 5), performing best on 50% of the datasets; Auto-sklearn performed best on 27% and TPOT on 20%.
Our proposed approach is important due to its flexibility (in utilizing existing AutoML techniques), effectiveness (against open source AutoML toolkits), and unique capability of our proposed scheme on a collection of binary classification data sets from UCI ML& OpenML repositories.
Our methodology
We map the AutoML problem to the black-box (gradient-free) optimization problem with mixed integer & continuous variables. This is the first time to employ alternating direction method of multipliers to decompose the problem into a sequence of sub-problems, which decouple the difficulties in AutoML and can each be solved more efficiently and effectively. It is also the first attempt to tackle the AutoML problem with black-box constraints in a theoretically-grounded manner.
There are two main challenges to address when designing, training and optimizing machine learning models automatically.
First, there is a coupling between algorithm selection and hyper-parameter design, leading to the complex structure in the AutoML problem.
Second, there exists the black-box nature of both optimization objective and constraints lacking any explicit functional form and gradients – optimization feedback is only available in the form of function and constraint evaluations.
Experimental results
We performed experiments on 30 datasets from OpenML and Kaggle. We considered time to predictive performance curves; repeated multiple times for statistical significance; compared to widely used (and very successful) open-source libraries; and evaluated the utility of the proposed de-coupling (operator-splitting).
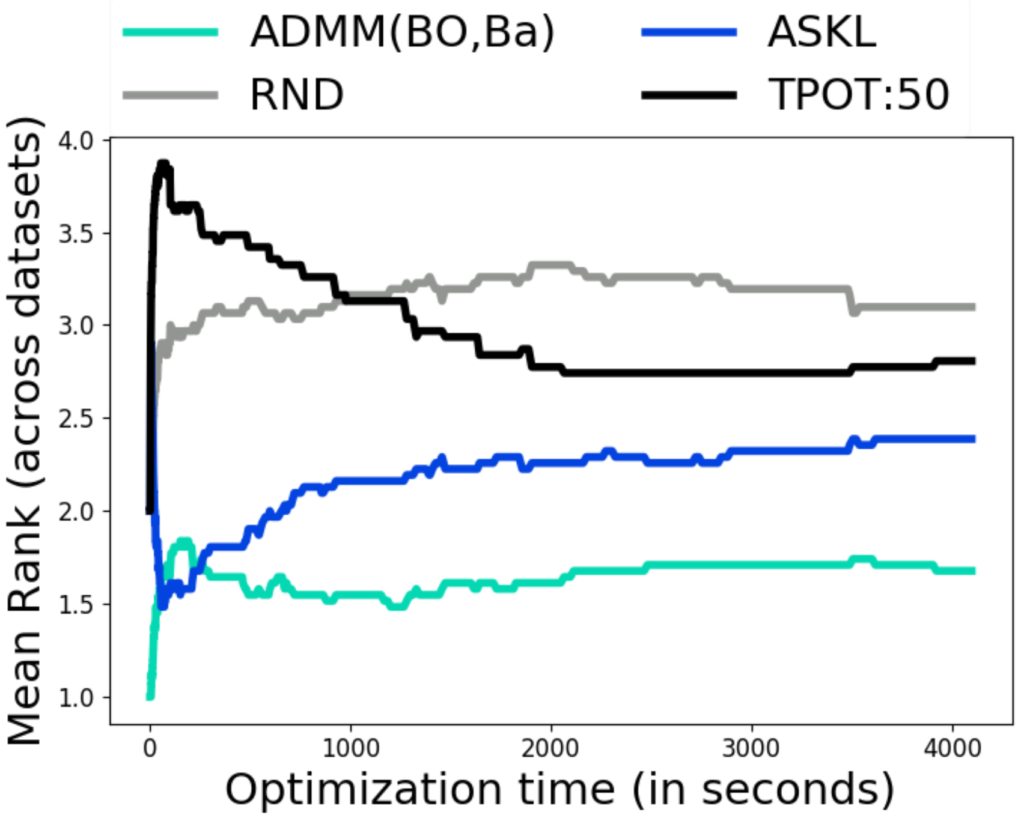
Figure 1: Average rank (across 30 datasets of mean performance across 10 trials – lower rank is better.
We also demonstrate that the proposed decoupling leads to massive improvements (speedups for same objective; much better objective for same run time) and achieved strong performance against widely used open source libraries. This, showing the novel capability of handling black-box constraints with a real world credit approval application.
Summary: Beyond single objective AutoML
In summary, our proposed scheme is one of the first ways to systematically move beyond a single objective AutoML to handle multiple constraints without a significant computational overhead. This combination of flexibility and efficiency represents an important step in the pursuit of automated machine learning.
Please cite our work using the BibTeX below.
@article{Liu_Ram_Vijaykeerthy_Bouneffouf_Bramble_Samulowitz_Wang_Conn_Gray_2020, title={An ADMM Based Framework for AutoML Pipeline Configuration}, volume={34}, url={https://ojs.aaai.org/index.php/AAAI/article/view/5926}, DOI={10.1609/aaai.v34i04.5926}, abstractNote={<p>We study the AutoML problem of automatically configuring machine learning pipelines by jointly selecting algorithms and their appropriate hyper-parameters for all steps in supervised learning pipelines. This <em>black-box</em> (gradient-free) optimization with <em>mixed</em> integer & continuous variables is a challenging problem. We propose a novel AutoML scheme by leveraging the alternating direction method of multipliers (ADMM). The proposed framework is able to (i) decompose the optimization problem into easier sub-problems that have a reduced number of variables and circumvent the challenge of mixed variable categories, and (ii) incorporate black-box constraints alongside the black-box optimization objective. We empirically evaluate the flexibility (in utilizing existing AutoML techniques), effectiveness (against open source AutoML toolkits), and unique capability (of executing AutoML with practically motivated black-box constraints) of our proposed scheme on a collection of binary classification data sets from UCI ML & OpenML repositories. We observe that on an average our framework provides significant gains in comparison to other AutoML frameworks (Auto-sklearn & TPOT), highlighting the practical advantages of this framework.</p>}, number={04}, journal={Proceedings of the AAAI Conference on Artificial Intelligence}, author={Liu, Sijia and Ram, Parikshit and Vijaykeerthy, Deepak and Bouneffouf, Djallel and Bramble, Gregory and Samulowitz, Horst and Wang, Dakuo and Conn, Andrew and Gray, Alexander}, year={2020}, month={Apr.}, pages={4892-4899} }