Layer-wise federated learning with FedMA
Authors
Authors
- Hongyi Wang
- Mikhail Yurochkin
- Yuekai Sun
- Dimitris Papailiopoulos
- Yasaman Khazaeni
Edited by


Authors
- Hongyi Wang
- Mikhail Yurochkin
- Yuekai Sun
- Dimitris Papailiopoulos
- Yasaman Khazaeni
Edited by
Published on
09/25/2019
Categories
Federated learning allows edge devices to collaboratively learn a shared model under the orchestration of a central server while keeping the training data on device, decoupling the ability to do model training from the need to store the data in the cloud. Though federated learning mitigates many of the data privacy risks and communication costs, it faces challenges with data heterogeneity, bandwidth limitations, and device availability. In our paper, Federated Learning with Matched Averaging, selected as an oral presentation in ICLR 2020, we propose Federated matched averaging (FedMA) algorithm that handles data heterogeneity while improving communication efficiency in federated learning.
Advances in Federated Learning
The first federated learning algorithm was Federated Averaging (FedAvg), proposed in 2016. In FedAvg, parameters of local models are averaged element-wise with weights proportional to sizes of the client datasets. One major shortcoming of FedAvg is that coordinate-wise averaging of weights may have drastic detrimental effects on the performance of the averaged model and adds significantly to the communication burden. This issue arises due to the permutation invariance of neural network (NN) parameters, i.e. for any given NN, there are many variants of it that only differ in the ordering of parameters.
In ICML 2018, our MIT-IBM colleagues proposed Probabilistic Federated Neural Matching (PFNM). PFNM addresses the above problem by matching the neurons of client NNs before averaging them. PFNM further utilizes Bayesian nonparametric methods to adjust global model size according to the heterogeneity in the data. PFNM has better performance and communication efficiency than FedAvg. Unfortunately, the method only works on simple architectures (e.g. fully connected NNs with limited depth).
In our new paper Federated Learning with Matched Averaging, we first demonstrate how PFNM can be applied to CNNs and LSTMs, but we find that it is lacking in performance when applied to deep architectures (e.g., VGG-9). To address this issue, we propose a new method called Federated Matched Averaging (FedMA), a new layers-wise federated learning algorithm for modern CNNs and LSTMs that appeal to Bayesian nonparametric methods to account for the heterogeneity in the data. We show empirically that FedMA not only reduces the communications burden, but also outperforms state-of-the-art federated learning algorithms.
The Algorithmic Design of FedMA
The proposed FedMA algorithm uses the following layer-wise matching scheme. First, the data center gathers only the weights of the first layers from the clients and performs one-layer matching to obtain the first layer weights of the federated model. A data center then broadcasts these weights to the clients, which proceed to train all consecutive layers on their datasets, keeping the matched federated layers frozen. This procedure is then repeated up to the last layer for which we conduct a weighted averaging based on the class proportions of data points per client.
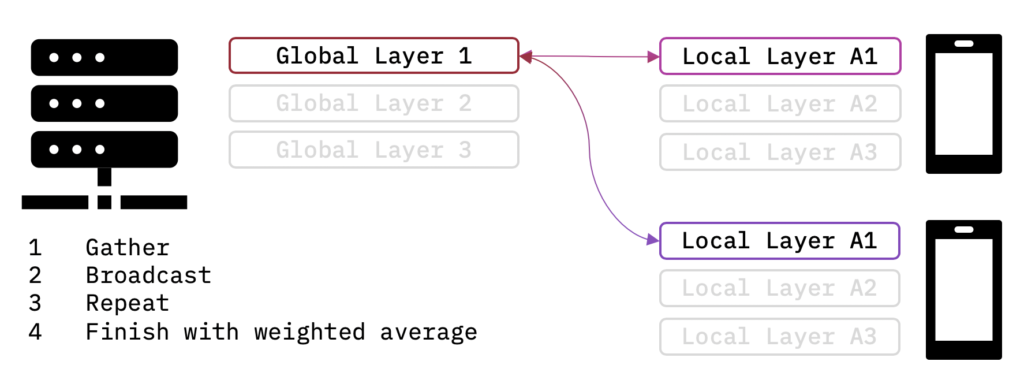
The most novel part of the FedMA algorithm is the layer-wise matching followed by local retraining methodology, which allows the algorithm to work well on modern deep CNNs and LSTMs.
Another interesting novelty is our solution for matching the hidden-to-hidden layer in LSTM. While solving the problem directly leads to a NP-hard problem, we relaxed it by using linear assignment corresponding to input-to-hidden weights to find the permutations, but account for the special permutation structure of the hidden-to-hidden weights when averaging them.
Experiments
To evaluate FedMA, we compared it to state-of-the-art baseline methods FedAvg and FedProx over three real-world datasets i.e. MNIST, CIFAR-10, and Shakespeare.
Communication efficiency and convergence rates. First we study the communication efficiency and convergence rates of FedMA. Our goal is to compare our method to FedAvg and FedProx in terms of the total message size exchanged between data center and clients and the number of communication rounds. Experimental results indicate that FedMA outperforms FedAvg and FedProx in all scenarios with its advantage especially pronounced when we evaluate convergence as a function of the message size.
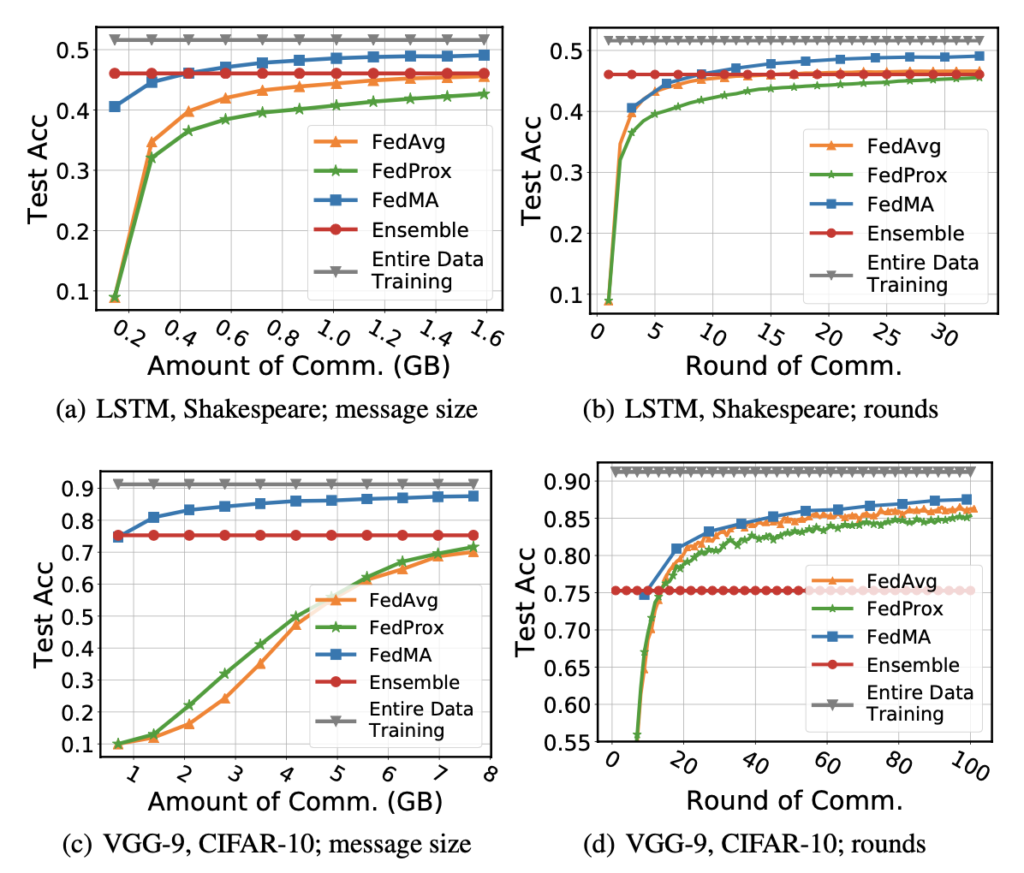
Figure 2: Convergence rates of various methods in two federated learning scenarios: training VGG-9 on CIFAR-10 with J = 16 clients and training LSTM on Shakespeare dataset with J = 66 clients.
Data efficiency. Our second experiment studies data efficiency of FedMA. The challenge here is that when new clients join the federated system, they each bring their own version of the data distribution, which, if not handled properly, may tamper the performance despite the growing data size across the clients. Our results indicate that performance of FedMA improves when new clients are added to the federated learning system, while FedAvg deteriorates.
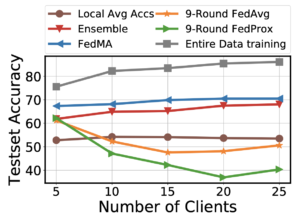
Figure 6: Data efficiency under the increasing number of clients.
Mitigating AI bias. In the final experiment we demonstrate that FedMA has the ability to handle data bias. Real world data often exhibits multimodality, e.g. geodiversity. It has been shown that an observable Amerocentric and Eurocentric bias is present in the widely used ImageNet dataset. Classifiers trained on such data “learn” these biases and perform poorly on the under-represented domains (modalities) since spurious correlation between the corresponding dominating domain and class can prevent the classifier from learning meaningful relations between features and classes (e.g., bride and dress color). In this study we argue that FedMA can handle this type of problem. If we view each domain, e.g. geographic region, as one client, local models will not be affected by the aggregate data biases and learn meaningful relations between features and classes. FedMA can then be used to learn a good global model alleviating biases. Our results suggest that FedMA may be of interest beyond federated learning, where entire data training is often the performance upper bound, but also to eliminate data biases outperforming entire data training.
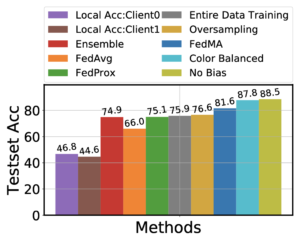
Figure 4: Performance on skewed CIFAR-10 dataset. We see that entire data training performs poorly in comparison to the regular (i.e. No Bias) training and testing on CIFAR-10 dataset without any grayscaling.
Summary
FedMA is a novel federated learning algorithm with state-of-the-art performance, and the added potential for mitigating AI bias. This can have a large impact on scaling up current real-world federated learning applications with heterogeneous client data distributions and limited communication bandwidth.
In the future, we want to extend FedMA to improve federated learning of LSTMs using approximate quadratic assignment solutions from the optimal transport literature, and enable additional deep learning building blocks, e.g. residual connections and batch normalization layers. We also believe it is important to explore fault tolerance of FedMA and study its performance on the larger datasets, particularly ones with biases preventing efficient training even when the data can be aggregated, e.g. Inclusive Images NeurIPS 2018 competition.
Please cite our work using the BibTeX below.
@inproceedings{
Wang2020Federated,
title={Federated Learning with Matched Averaging},
author={Hongyi Wang and Mikhail Yurochkin and Yuekai Sun and Dimitris Papailiopoulos and Yasaman Khazaeni},
booktitle={International Conference on Learning Representations},
year={2020},
url={https://openreview.net/forum?id=BkluqlSFDS}
}