The Sound of Pixels
Authors
Authors
- Hang Zhao
- Chuang Gan
- Andrew Rouditchenko
- Carl Vondrick
- Josh McDermott
- Antonio Torralba
Authors
- Hang Zhao
- Chuang Gan
- Andrew Rouditchenko
- Carl Vondrick
- Josh McDermott
- Antonio Torralba
Published on
04/09/2018
Categories
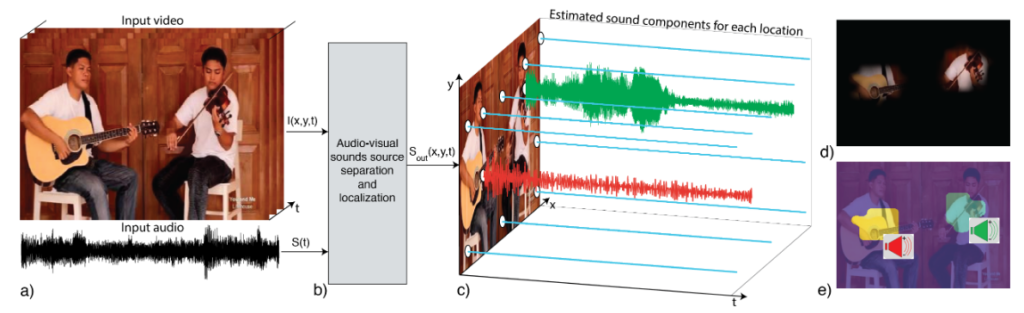
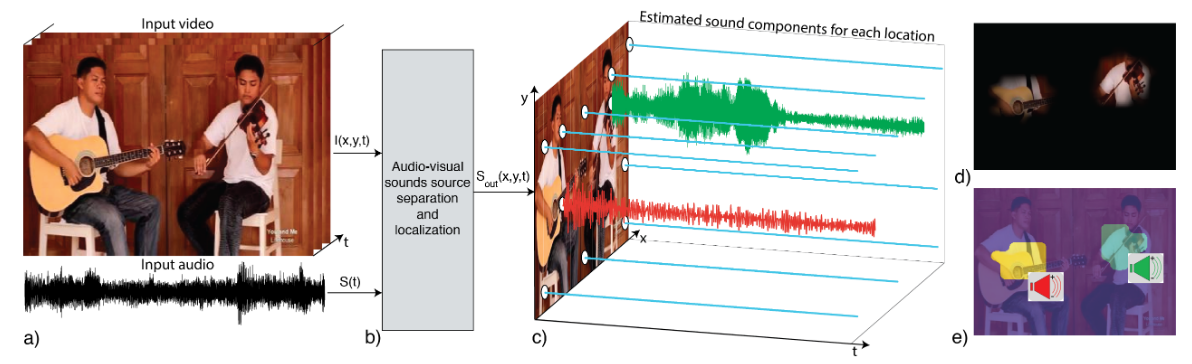
We introduce PixelPlayer, a system that, by leveraging large amounts of unlabeled videos, learns to locate image regions which produce sounds and separate the input sounds into a set of components that represents the sound from each pixel. Our approach capitalizes on the natural synchronization of the visual and audio modalities to learn models that jointly parse sounds and images, without requiring additional manual supervision. Experimental results on a newly collected MUSIC dataset show that our proposed Mix-and-Separate framework outperforms several baselines on source separation. Qualitative results suggest our model learns to ground sounds in vision, enabling applications such as independently adjusting the volume of sound sources.
Please cite our work using the BibTeX below.
@article{DBLP:journals/corr/abs-1804-03160,
author = {Hang Zhao and
Chuang Gan and
Andrew Rouditchenko and
Carl Vondrick and
Josh H. McDermott and
Antonio Torralba},
title = {The Sound of Pixels},
journal = {CoRR},
volume = {abs/1804.03160},
year = {2018},
url = {http://arxiv.org/abs/1804.03160},
archivePrefix = {arXiv},
eprint = {1804.03160},
timestamp = {Mon, 13 Aug 2018 16:47:59 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-1804-03160.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}