SenSR: the first practical algorithm for individual fairness
Authors
Authors
- Mikhail Yurochkin
- Amanda Bower
- Yuekai Sun
Edited by


Algorithmic fairness a sub-field of Machine Learning that studies the questions related to formalizing fairness in algorithms mathematically and developing techniques for training and auditing ML systems for bias and unfairness. In our paper, Training individually fair ML models with sensitive subspace robustness, published in ICLR 2020, we consider training machine learning models that are fair in the sense that their performance is invariant under certain sensitive perturbations to the inputs. For example, the performance of a résumé screening system should be invariant under changes to the gender and/or ethnicity of the applicant. We formalize this notion of algorithmic fairness as a variant of individual fairness and develop a distributionally robust optimization approach to enforce it during training. We also demonstrate the effectiveness of the approach on two ML tasks that are susceptible to gender and racial biases.
AI fairness
In today’s data-driven world, machine learning (ML) systems are increasingly used to make high-stakes decisions in domains like criminal justice, education, lending, and medicine. For example, a judge may use an algorithm to assess a defendant’s chance of re-offending before deciding to detain or release the defendant. Although replacing humans with ML systems appear to eliminate human biases in the decision-making process, they can perpetuate or even exacerbate biases in the training data. Such biases are especially objectionable when it adversely affects underprivileged groups of users. The most obvious remedy is to remove the biases in the training data, but carefully curating the datasets that modern ML systems are trained on is impractical. This leads to the challenge of developing ML systems that remain “fair” despite biases in the training data.
But what is fair?
There are two major families of definitions of fairness: (1) group fairness; (2) individual fairness. Group fairness requires certain constraints to be satisfied at the population level, e.g. proportion of hired job applicants should be similar across different demographic groups. Individual fairness (also known as Lipschitz fairness) states that hiring decisions for any pair of similar applicants (e.g. equally qualified applicants with different names) should be the same.
Most prior work on algorithmic fairness focuses on enforcing group fairness, but this notion suffers from a few drawbacks.
The basic idea of group fairness is to compare the average outputs of an AI algorithm on different groups of users. For example, suppose we want to determine the credit limit of applicants to a credit card via an AI algorithm. Group fairness with respect to gender could mean enforcing that the average credit limits for male and female users are equal. The main drawback that we wish to address is it is possible for an algorithm to be group-wise fair, but blatantly unfair from the perspective of individual users.
Consider the case of a lender algorithmically determining the credit limits, where the lender wants to avoid blatant gender discrimination. It is possible for an AI algorithm to give all women in California a very high credit limit (while keeping the credit limits of other women low) to bring up the average credit limit for women to a level that is similar to the average credit limit of men. Although this algorithm satisfies group fairness (the average credit limit for women is similar to that for men), the algorithm is blatantly unfair from the perspective of women not in California.
To address problems like these (originally presented in the seminal work of Dwork et al. in 2011), we consider a more individualized notion of algorithmic fairness in our work.
The SenSR Algorithm
We propose the Sensitive Subspace Robustness (SenSR) algorithm, which can be used to enforce individual fairness when training a wide range of machine learning models including neural networks. SenSR is the first practical algorithm in the literature for achieving individual fairness. It is quite easy to implement and to apply across a variety of tasks and models as demonstrated by our experiments.
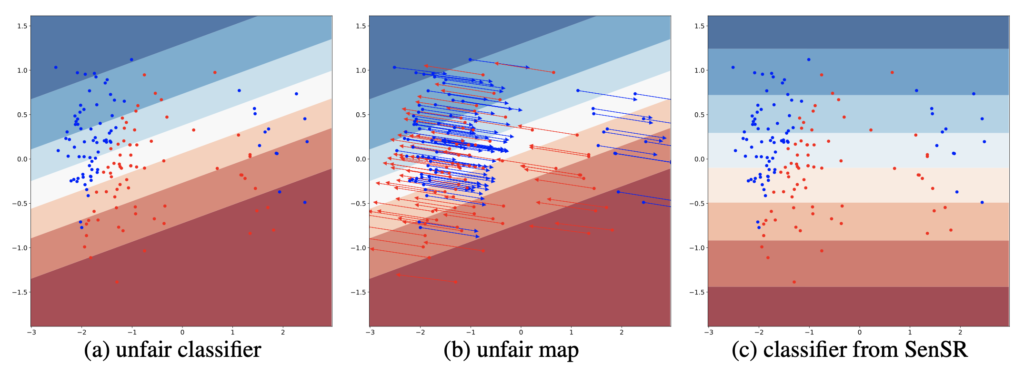
Figure 1: Figure (a) depicts a binary classification dataset in which the minority group shown on the right of the plot is underrepresented. This tilts the logistic regression decision boundary in favor of the majority group on the left. Figure (b) shows the unfair map of the logistic regression decision boundary. It maps samples in the minority group towards the majority group. Figure (c) shows an algorithmically fair classifier that treats the majority and minority groups identically.
The story behind SenSR serves as a good reminder of the importance of cross-pollination across sub-fields in AI. We began this work on the theoretical side, seeking a generalization of individual fairness guarantees. It so happened we were also participating in a reading group on adversarial robustness, and from this a novel idea emerged: perhaps we could cast the problem of training individually fair ML model as training ML models whose outputs are invariant under certain sensitive perturbations to the inputs. This is the insight that led to SenSR.
Consider a case in résumé screening system, where the output (whether to follow up with an applicant) should not depend on the perceived ethnicity or gender of the applicant. First, we “attack” the training data set by perturbing perceptions of ethnicity and gender (e.g. by changing the applicant’s name). Drawing on methods for hardening ML models against such adversarial perturbations, the SenSR algorithm trains a résumé screening system so that its decision is robust against these perceptions of ethnicity or gender.
Experiments
In our paper, we present two experimental results:
First, we look at the Adult dataset, which is commonly used in the fairness literature. We used it to demonstrate the efficacy of our method in comparison to previous methods. The task is to predict if an individual earns over $50,000 per year given various attributes (e.g., age, educations, hours worked per week as well as gender, race and marital status). We trained a neural network using our methodology and showed that it has lower performance gaps (i.e. biases) across race and gender groups than neural networks trained with some of the previous fairness methods. We also demonstrated significant improvements in individual fairness by checking if the AI predictions are unchanged when altering husband/wife status, gender or race of the individuals in the test data.
Our second experiment was inspired by the recent studies of bias in word embeddings. The problem presented in prior literature is as follows: AI for sentiment prediction trained using word embeddings can be biased in a sense that it thinks that typical Caucasian names are more positive than typical African-American names. Our technique combats this. It allows us to perform sentiment prediction without discriminating against names of people while preserving the high sentiment classification quality enabled by the word embeddings.
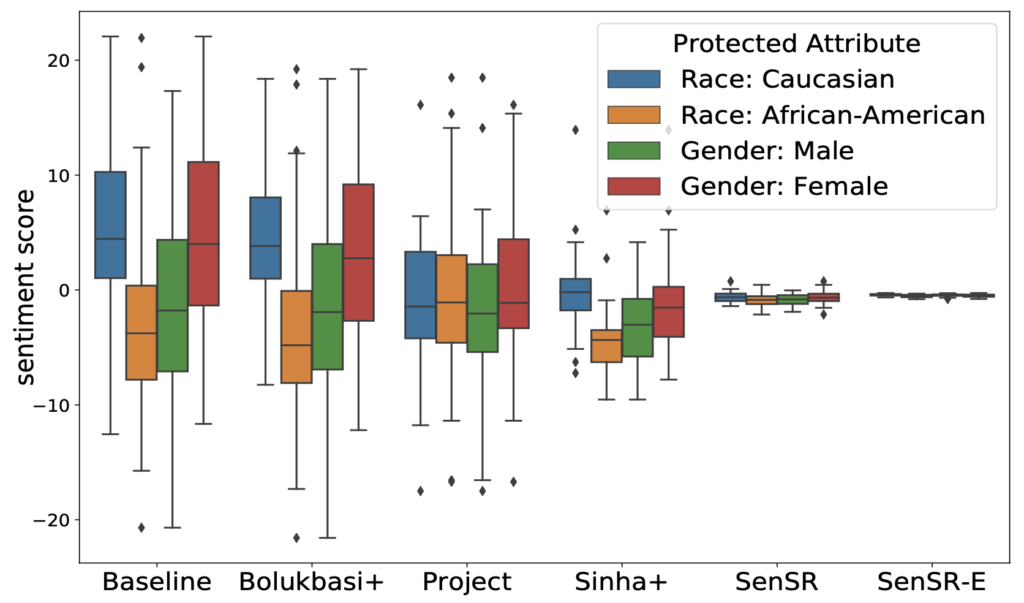
Figure 2: Box-plots of sentiment scores in our second experiment. The visualization shows the dramatic improvement of SenSR relative to alternative methods.
Summary
Individual fairness was one of the first notions of fairness, but training ML models that abide by it has eluded practitioners for many years. If machine learning is to be adopted and positively impactful in decision-making and decision-support roles, not to mention compliant with laws and regulations, we need to train models that are provably fair. We are proud to share this as it represents an important step towards trustworthy machine learning.
Please cite our work using the BibTeX below.
@inproceedings{yurochkin2020training,
title={Training individually fair ML models with sensitive subspace robustness},
author={Yurochkin, Mikhail and Bower, Amanda and Sun, Yuekai},
booktitle={International Conference on Learning Representations, Addis Ababa, Ethiopia},
year={2020}
}