Class-wise rationalization: teaching AI to weigh pros and cons
Authors
Authors
Edited by

Authors
Edited by
Published on
12/09/2019
Imagine you’re picking a hotel to stay at. It’s your anniversary so you want everything to be perfect. Your partner is particular about certain things, so you’re not going to rely on the star rating alone; you’re going to read the reviews to weigh the specific pros and cons. From this, you’ll develop a rationale for your selection and hopefully enjoy a special night with your special person. If something does go wrong, at least you can explain your rationale and hopefully get brownie points for trying. It’s the thought that counts, right?
Weighing pros and cons (and explaining them to ourselves and others) is a daily exercise of human intelligence. Some people get really into it (you know who you are). Computers on the other hand, haven’t really been able to do this. At least until now.
In our paper, A Game Theoretic Approach to Class-wise Selective Rationalization, presented in NeurIPS 2019, we present a new method called Class-wise Adversarial Rationalization (CAR). It is the first method that can discover class-dependent rationales. In our hotel example, your hotel pros and cons are two separate classes both contributing to a single rationale for your ultimate selection. Importantly, just like the hotel example, CAR is more explainable by virtue of distinguishing between classes.
A primer on deep rationalization
This paper is the latest in an important line of work we’re pursuing at the MIT-IBM Watson AI Lab. We call this work Deep Rationalization. You can think of it like this.
A child asks “Why can’t I eat this jelly bean?” A parent replies, “Because I said so.” The child learns she can’t eat the jelly bean (at least not while Dad is watching), but she doesn’t learn *why*. So she repeats many such questions before learning what flies. Dad might save himself a headache if he explained, “Jelly beans are pure sugar and such foods give you cavities, which really hurt. That’s why we don’t eat pure sugar foods.” In contrast, today’s AI models are like the lazy Dad who actually costs himself more work in the long run.
For all the massive amounts of training data fed to AI models, the general absence of basic rationalizations in the labels means the models are hard to train and hard to explain. This may have been acceptable early on, but, AI is now reaching adolescence and “Because I said so” is no longer cutting it.
Our two-pronged goal is 1) to radically reduce the number of labelled examples a model needs to learn, and 2) to radically improve explainability.
Selective Rationalization
Selective rationalization refers to the process of finding rationales. A rationale is a hard selection of input features that are sufficient to explain the output prediction. In natural language processing (NLP), a rationale is a selection of text-spans that are short and coherent, and sufficient for the correct prediction.
As an example, below is a beer review, and the output prediction is the rating of the beer appearance. The rationales are short sentences that explain why the appearance achieves 5 stars. A possible set of rationales are highlighted in green.

The class problem with today’s rationalization techniques
Existing rationalization algorithms have one limitation. They only look for rationales that support the labeled class. For example, given a negative hotel review like the one below, today’s models can only find the explanation for the negative sentiment. What if we want to also find rationales supporting positive sentiment i.e. the counterfactual rationales? This would allow a more structural interpretation of deep learning models, much like the weighing of pros and cons, especially when the input evidence is complicated and mixed.

Introducing Class-wise Adversarial Rationalization (CAR)
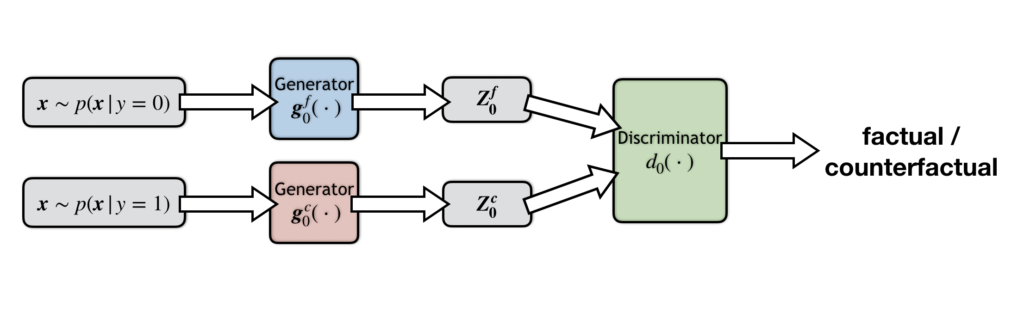
Drawing on insights from game theory, we present a new method called Class-wise Adversarial Rationalization, or CAR, which can find rationales explaining any given class. Consider a binary sentiment classification task, where there are two classes, the negative class (or class 0) and the positive class (or class 1). Under this setting, the CAR structure consists of two groups, the class-0 group and the class-1 group. The class-0 group aims to find class-0 rationales, or more concretely the cons, from input text. The class-1 group aims to find the pros.
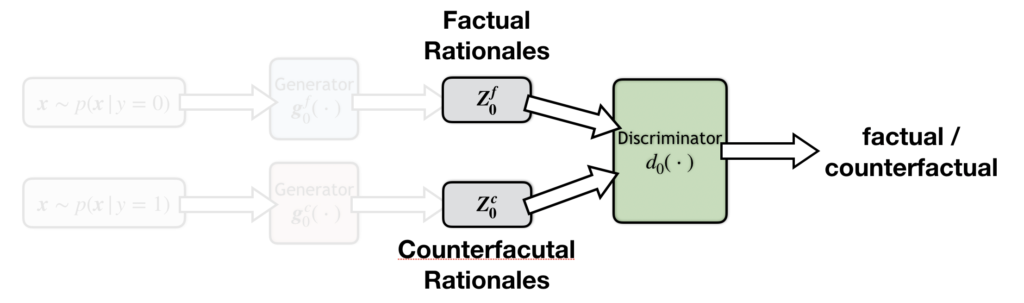
Let’s focus on the class-0 group. Below is the structure diagram of this group.
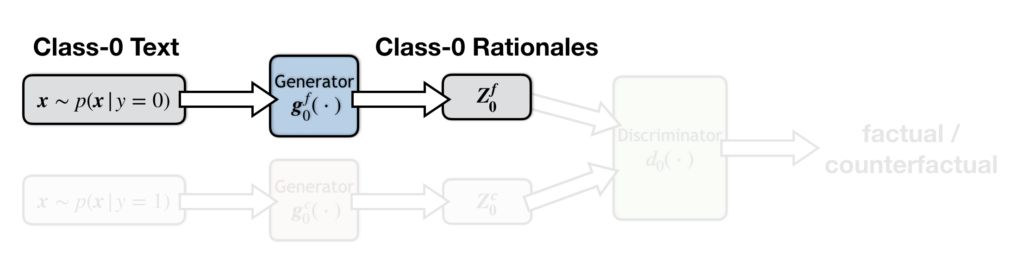
In this group, there is a factual generator (below), which generates class-zero rationales (cons) from class-zero texts (negative texts). In this case, the rationales that the generator aims to find are consistent with the text label. Hence the generator is called factual.
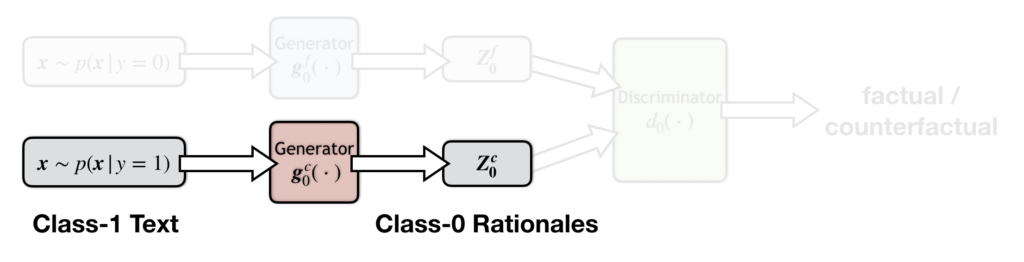
Next we have a counterfactual generator (below), which also generates class-zero rationales (cons), but from class-one texts (positive texts). In this case, the rationales that the generator aims to find are at odd with the text label. Hence the generator is called counterfactual.
Finally, we have a discriminator (below), which distinguishes factual from counterfactual rationales.
The CAR algorithm is trained adversarially. Specifically, both factual and counterfactual generators try to convince the discriminator that their rationales are factual. The factual and counterfactual generators are playing an adversarial game with each other, one trying to help the discriminator, and the other trying to fool it.
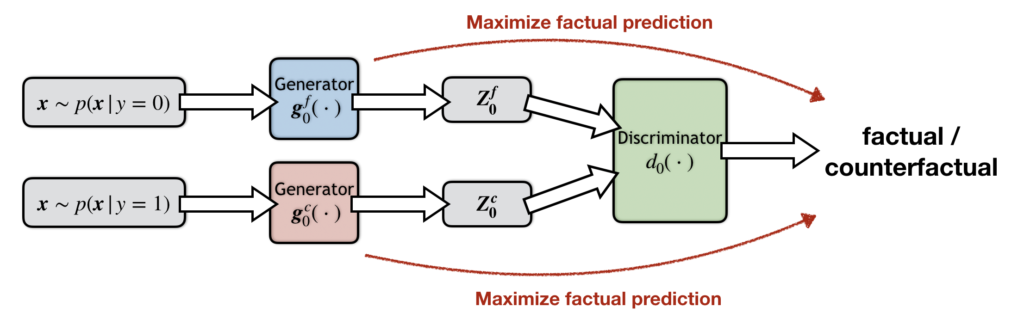
As an intuitive explanation of why it works, notice the two generators are competing adversarially. In order to convince the discriminator, both generators must work hard to find evidence that truly explains the class. No cop-out rationales.
Results using CAR for hotel selection
Consider a hotel review dataset, where each review covers three aspects of a hotel – location, service and cleanliness – and each aspect carries a positive or negative label. We can apply CAR to discover the factual and counterfactual rationales behind each score.
Here are some examples of factual and counterfactual rationales highlighted by CAR, where the class-0 positive rationales are highlighted in blue, and class-1 negative rationales are highlighted in red. We can see clear pros and cons in the highlighting. Our objective evaluation also verifies that these rationales agree with human annotations.

Even more interesting is this: we conducted a survey in which subjects are presented with the rationales and asked to guess the class (positive or negative) as well as the aspect (location, service and cleanliness). See the respondent view below.
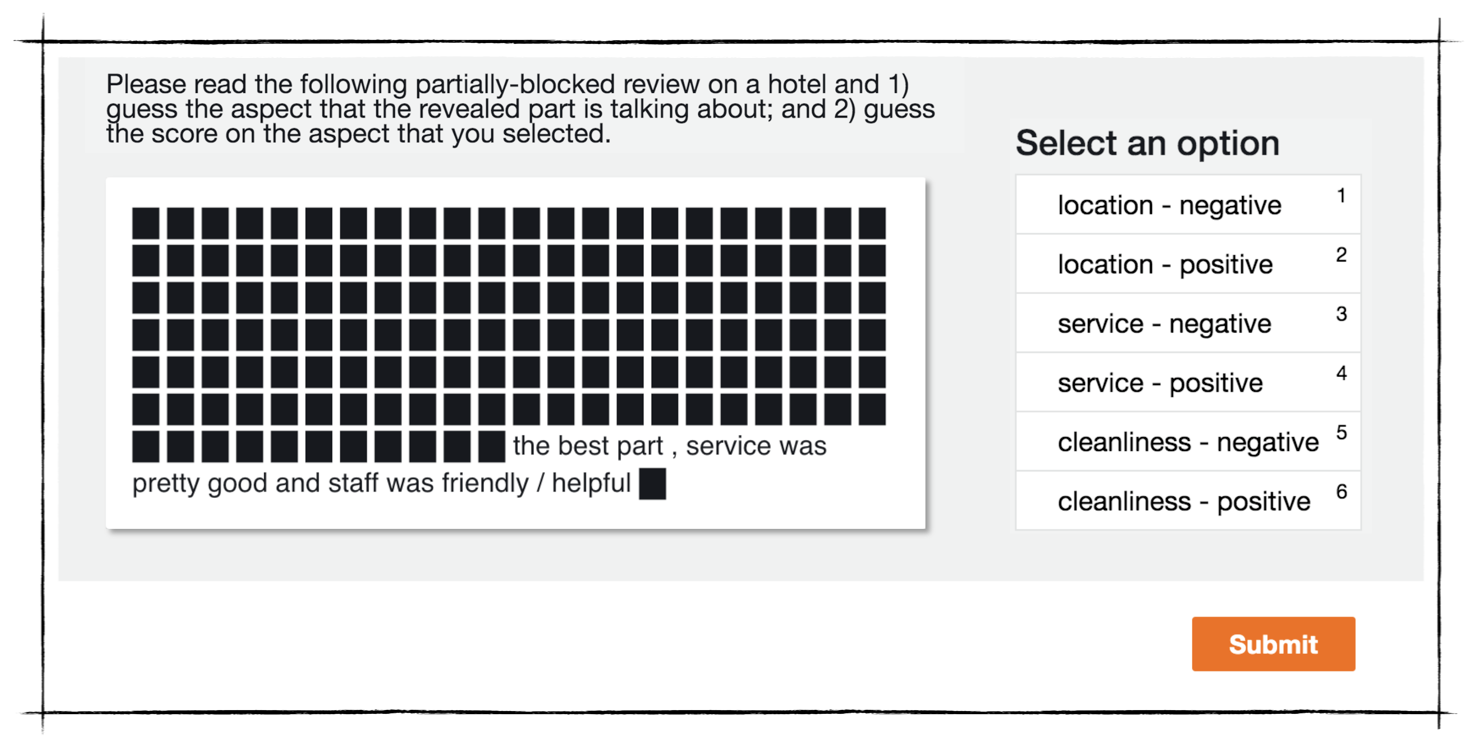
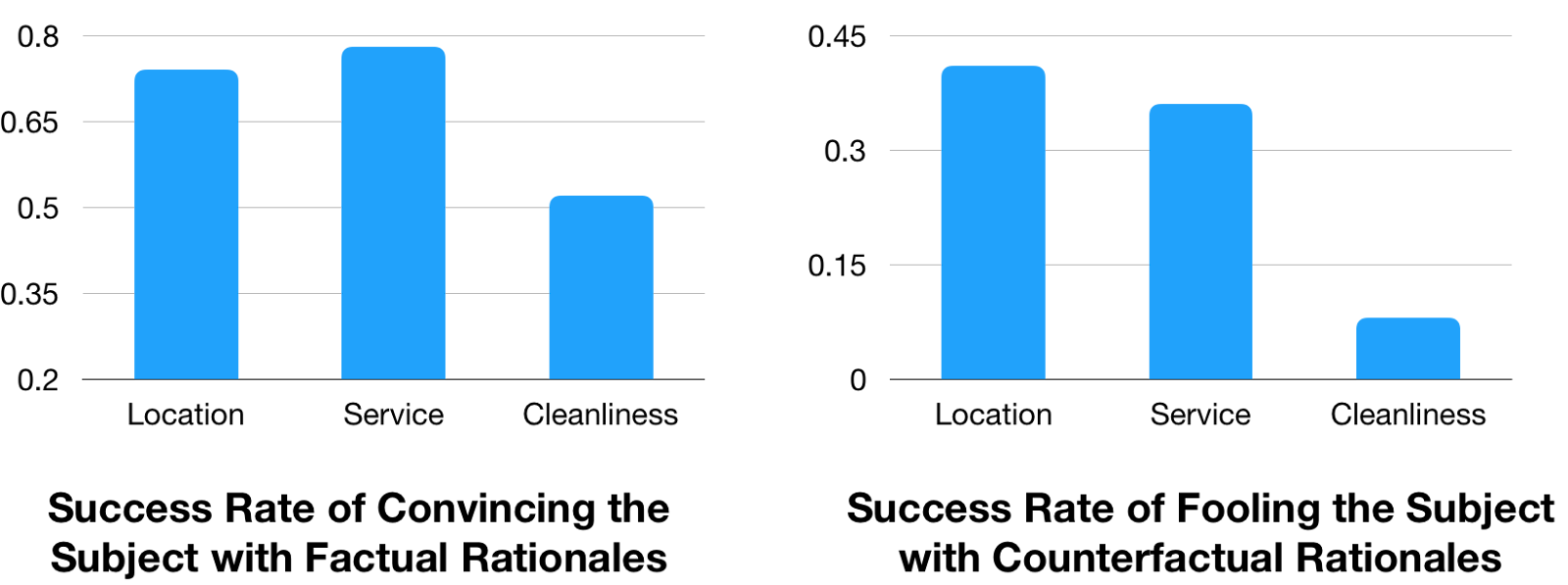
The survey results below show that CAR is able to correctly convince the subjects with factual rationales (left), and fool the subjects with counterfactual rationales (right) with a very high success rate, as shown in the figure below. Note that there are a total of six options, so a random guess would yield only a 16.7% success rate. Most of the results below are significantly higher than a random guess.
Explainable AI is attainable
The business community, civil servants, and the general public have all made one thing clear: explainability in AI is a non-negotiable. Moreover, making AI accessible and scalable requires reducing our dependence on massive amounts of costly annotated training data. Both require higher levels of reasoning emulating human intelligence. By enabling models to do things like weigh pros and cons, Class-wise Adversarial Rationalization is an important step forward.
When AI was very young, we didn’t have much choice. AI has its driver’s license now, so it’s time to stop settling for, “Because I said so.” You can take CAR for a spin with our open-source code here.
Please cite our work using the BibTeX below.
@misc{chang2019game,
title={A Game Theoretic Approach to Class-wise Selective Rationalization},
author={Shiyu Chang and Yang Zhang and Mo Yu and Tommi S. Jaakkola},
year={2019},
eprint={1910.12853},
archivePrefix={arXiv},
primaryClass={cs.LG}
}