Learning to learn with distributional signatures for text data
Authors
Authors
- Yujia Bao
- Menghua Wu
- Shiyu Chang
- Regina Barzilay
Edited by

Authors
- Yujia Bao
- Menghua Wu
- Shiyu Chang
- Regina Barzilay
Edited by
Published on
08/16/2019
Categories
Learning to Learn
As humans, education is an essential activity in the development of our cognition. Perhaps more important than the specific knowledge we acquire in any given year in a classroom (let’s be honest, we forget much of it), school is an exercise in learning to learn. This ability is what allows us the freedom to take on new challenges and apply ourselves in different ways. The better we are at it, the more quickly we can pick up new things. In computer science, we use the term meta-learning to describe this “learning to learn” activity. The better we are at it, the more we can enable few-shot and zero-shot learning abilities wherein we can perform new tasks or evaluate new datasets with little or no prior exposure.
Meta-learning has shown strong performance in computer vision, where low-level patterns are transferable across learning tasks. For example, a model trained to identify numbers 0 to 9 can easily be adapted to identify the English alphabet. However, directly applying this approach to textual data is challenging because lexical features highly informative for one task may be insignificant for another. The challenge involves the degree of transferability of the underlying representation learned across different classes. Whereas in computer vision, low-level patterns (such as edges) and their corresponding representations can be shared across tasks, the situation is different for language data where most tasks operate at the word level. To distinguish between sports news and politics news requires an entirely different set of words than if we were distinguishing between technology trends and medical research.
Distributional Signatures
In our new paper, Few-shot Text Classification with Distributional Signatures, we demonstrate that despite these variations, we can effectively transfer representations across classes and thereby enable learning in a low-resource regime. Instead of just considering words, we consider the underlying characteristics in the distribution of words. We call these distributional signatures and we consider their behavior across different types of tasks. Within the meta-learning framework, distributional signatures enable us to transfer attention across tasks, which can consequently be used to weight the lexical representations of words.
One broadly used example of distributional signatures is tf-idf weighting, which explicitly specifies word importance in terms of its frequency in a document collection, and its skewness within a specific document. Building on this idea, we wanted to learn to utilize distributional signatures in the context of cross-class transfer. In addition to word frequency, we assessed word importance with respect to a specific class. This latter relation cannot be reliably estimated of the target class due to the scarcity of labeled data. However, we discovered we can obtain a noisy estimate of this indicator by utilizing the few provided training examples for the target class, then further refining this approximation within the meta-learning framework.
Model Architecture
The model we developed consists of two components. The first is an attention generator, which translates distributional signatures into attention scores that reflect word importance for classification. Informed by the attention generator’s output, we use a ridge regressor to quickly learn to make predictions after seeing only a few training examples (i.e. few-shot learning). The attention generator is shared across all episodes, while the ridge regressor is trained from scratch for each individual episode. The ridge regressor’s prediction loss provides supervision for the attention generator.
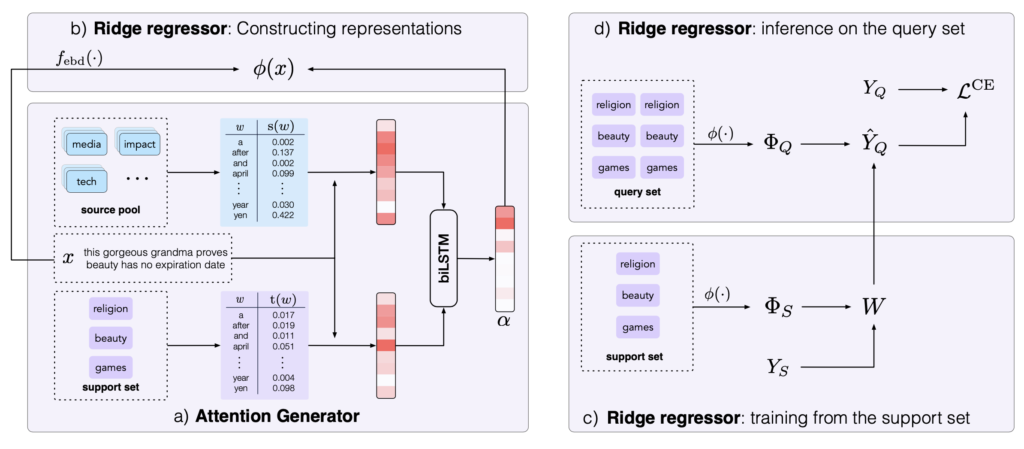
Figure 5: Illustration of our model for an episode with N = 3, K = 1, L = 2. The attention generator translates the distributional signatures from the source pool and the support set into an attention α for each input example x (a). The ridge regressor utilizes the generated attention to weight the lexical representations (b). It then learns from the support set (c) and makes predictions over the query set (d).
Experiments
Data
We evaluate our approach on five text classification datasets and one relation classification dataset.
- 20 Newsgroups is comprised of informal discourse from news discussion forums (Lang, 1995). Documents are organized under 20 topics.
- RCV1 is a collection of Reuters newswire articles from 1996 to 1997 (Lewis et al., 2004). These articles are written in formal speech and labeled with a set of topic codes. We consider 71 second level topics as our total class set and discard articles that belong to more than one class.
- Reuters-21578 is a collection of shorter Reuters articles from 1987 (Lewis, 1997). We use the standard ApteMod version of the dataset. We discard articles with more than one label and consider 31 classes that have at least 20 articles.
- Amazon product data contains customer reviews from 24 product categories (He & McAuley, 2016). Our goal is to classify reviews into their respective product categories. Since the original dataset is notoriously large (142.8 million reviews), we select a more tractable subset by sampling 1000 reviews from each category.
- HuffPost headlines consists of news headlines published on HuffPost between 2012 and 2018 (Misra, 2018). These headlines split among 41 classes. They are shorter and less grammatical than formal sentences.
- FewRel is a relation classification dataset developed for few-shot learning (Han et al., 2018). Each example is a single sentence, annotated with a head entity, a tail entity, and their relation. The goal is to predict the correct relation between the head and tail. The public dataset contains 80 relation types
Baselines
In addition to the ridge regressor (RR) (Bertinetto et al., 2019), we evaluate two standard supervised learning algorithms and two meta-learning algorithms, which we call “NN” and “FT”. NN is a 1-nearest neighbor classifier under Euclidean distance. FT pre-trains a classifier over all training examples, then fine-tunes the network using the support set (Chen et al., 2019). MAML meta-learns a prior over model parameters, so that the model can quickly adapt to new classes (Finn et al., 2017). Prototypical network (PROTO) meta-learns a metric space for few-shot classification by minimizing the Euclidean distance between the centroid of each class and its constituent examples (Snell et al., 2017).
Results
We evaluated our model in both 5-way 1-shot and 5-way 5-shot settings. Our model consistently achieves the best performance across all datasets. On average, our model improves 5-way 1-shot accuracy by 7.5% and 5-way 5-shot accuracy by 3.9%, against the best baseline for each dataset. When comparing against CNN+PROTO, our model improves by 20.0% on average in 1-shot classification. The empirical results clearly demonstrate that meta-learners privy to lexical information consistently fail, while our model is able to generalize past class-specific vocabulary. Furthermore, a lexicon-aware meta-learner (CNN+PROTO) is able to overfit the training data faster than our model, but our model more readily generalizes to unseen classes.
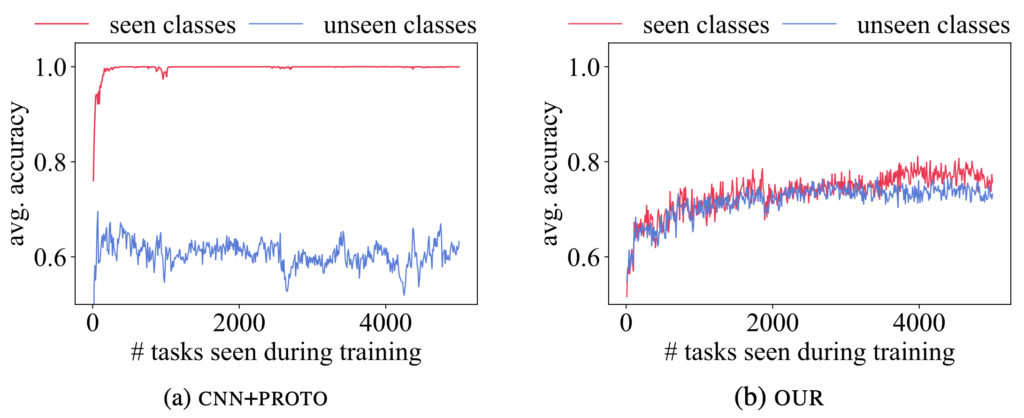
Figure 6: Learning curve of CNN+PROTO (left) v.s. OUR (right) on the Reuters dataset. We plot average 5-way 1-shot accuracy over 50 episodes sampled from seen classes (blue) and unseen classes (red). While OUR has weaker representational power, it generalizes better to unseen classes.
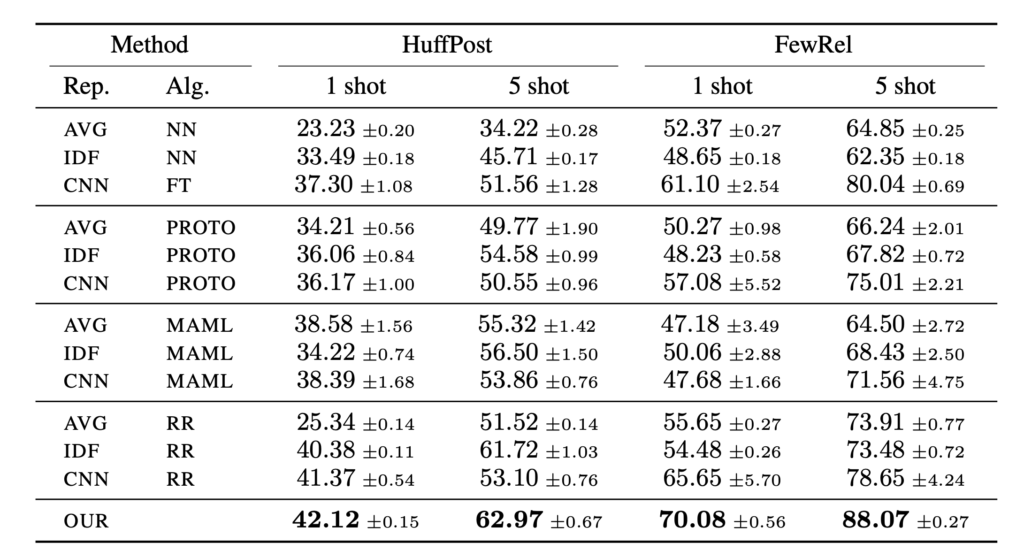
Table 2: 5-way 1-shot and 5-way 5-shot classification on HuffPost and FewRel using BERT.
Summary
A pitfall for students in any classroom is falling into rote memorization rather than true comprehension. The same can happen with AI models, and indeed our work is the first to identify the fact that today’s meta-learning algorithms only memorize features that are useful during meta-training and therefore fail to develop a robust understanding of textual content. As a result they fail to adapt quickly to new settings.
The main contribution of this paper, therefore, is not a specific set of delexicalised features for an end task (classification/parsing), but rather a new meta-learning approach towards generalizable representations. Meta-knowledge learned on top of distributional signatures can be used towards any downstream classifier to improve performance in low-resource settings. Moreover, from our experiments, we have provided the largest publicly available few-shot text classification benchmarks to the community. Our code (including all reported baselines) and data splits are available for reproducibility.
Please cite our work using the BibTeX below.
@inproceedings{
bao2020fewshot,
title={Few-shot Text Classification with Distributional Signatures},
author={Yujia Bao and Menghua Wu and Shiyu Chang and Regina Barzilay},
booktitle={International Conference on Learning Representations},
year={2020}
}