MCUNet: Tiny Deep Learning on IoT Devices
Authors
Authors
- Ji Lin
- Wei-Ming Chen
- Yujun Lin
- John Cohn
- Chuang Gan
- Song Han
Authors
- Ji Lin
- Wei-Ming Chen
- Yujun Lin
- John Cohn
- Chuang Gan
- Song Han
Published on
07/20/2020
Categories
This paper, MCUNet: Tiny Deep Learning on IoT Devices, details a new advancement that could help bring more AI than ever before to simple chips and IoT devices — everything from medical devices to home appliances. This unique system allows large neural networks to be condensed down onto tiny IoT devices, offering customizable deep learning architectures on smaller devices with limited memory and processing power.
This paper has been published as a spotlight in the 2020 Neural Information Processing Systems (NeurIPS) conference.
New IBM-MIT system brings AI to microcontrollers – paving the way to ‘smarter’ IoT
Smart homes are now all the rage, with smart speakers controlling your lights, your door lock, your fridge. But what if you didn’t want to use a smart speaker or any sophisticated computer to operate your devices? What if instead, a device like a lock had a cheap, tiny but powerful embedded AI that could recognize your face to open the door – and run on batteries for a year, no WIFi or smart speaker needed?
Enter microcontrollers of the future – the simplest, very small computers. They run on batteries for months or years and control the functions of the systems embedded in our home appliances and other electronics. They are all around us, but because they are so tiny – the size of a fingernail – and limited for memory and computation resources, it’s hard to make them ‘smart.’
A global team of researchers from MIT, National Taiwan University and the MIT-IBM Watson AI Lab want to change that. Led by Ji Lin – a PhD student in Professor Song Han’s lab at MIT’s Electrical Engineering & Computer Science (EECS) – their recent study could help put more AI into a microcontroller than ever before.
Presented at NeurIPS 2020, the research could also help inject more AI and ‘smartness’ into the Internet of Things (IoT). IoT describes the myriad of sensor-equipped connected devices that ‘talk’ to each other, like the chips that operate the brakes in your car, control your thermostat or a pacemaker implanted in your body.
Ji Lin collaborated with Prof. Song Han and Yujun Lin of MIT, Wei-Ming Chen of MIT and National University Taiwan, and John Cohn and Chuang Gan of the MIT-IBM Watson AI Lab. Together, they have developed a new system for optimizing AI for individual microcontrollers. Dubbed MCUNet, it consists of two complimentary techniques, TinyNAS and TinyEngine.
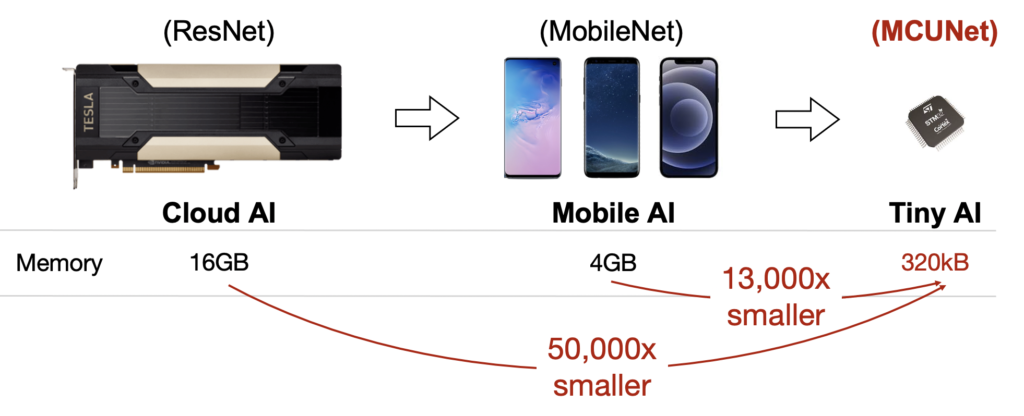
Tiny AI on IoT device is very challenging due to the limited memory resource of microcontrollers, which is four orders of magnitude less than mobile phones and GPUs. MCUNet provides an effective solution that efficiently utilizes the memory by co-designing compact neural network architecture and light-wight inference engine, bringing deep learning to IoT devices. (credits to: tinyml.mit.edu)
The techniques take AI models designed for bigger computers and optimize them for a specific microcontroller to get the most out of AI – meaning the highest accuracy at the highest performance. In other words, MCUNet helps the user to fit the most AI into the least amount of memory on a specific – very constrained – microcontroller. “This is fundamentally different from optimizing neural networks for mobile phones or desktop computers, since a microcontroller has no DRAM and no operating system,” says Song Han, assistant professor of MIT EECS. “It’s very challenging because of the available memory is three orders of magnitude less than mobile phones.”
The team has found that a microcontroller equipped with just the right AI components could do machine learning tasks like classifying images and recognizing speech much better than previous AI-boosted microcontrollers. “Compared to the well-known ImageNet benchmark, devices using the MCUNet system recognized images at a rate higher than 70 percent, higher than any reported solution on microcontrollers,” says Cohn, IBM Fellow for the MIT-IBM Watson AI Lab. And, he adds, they distinguished audio commands such as ‘turn on’ roughly three times faster than the most comparable previously published results.
The trick: co-optimization of the AI model design and the inferencing engine used to deploy it. It’s similar to packing a suitcase on a trip, says Cohn. “You can’t take your whole house with you, so you need to decide what’s really important for the trip and what will fit in the suitcase, right? Same here – and as you can’t try all the options, you have to be smart and optimize.”
The team did just that with the creation of TinyNAS, where ‘NAS’ stands for ‘neural architectural search,’ and TinyEngine – to help with optimizing AI.
When the right stuff matters
First, the researchers developed TinyNAS, a sophisticated algorithm that creates custom-sized networks to account for the different power capacities and memory sizes on microcontrollers. TinyNAS takes an AI model designed for a much bigger computer and reduces its structure without sacrificing too much speed and accuracy. It does so by generating compact neural networks with the best possible performance for a given microcontroller — with no unnecessary parameters.
“The problem is, you can’t possibly explore all the different variations and then evaluate them completely to see whether they meet the performance and accuracy constraints,” says Cohn. “Instead, TinyNAS uses sophisticated techniques to quickly explore the space of all possible smaller models, and then uses more detailed optimization to only test out the variance that look promising.”
Once TinyNAS has changed the architecture of the AI model, it passes that information to the second part of the system – the TinyEngine, whose purpose is to improve the efficiency of deploying that model on a microcontroller. The TinyEngine creates a special ‘schedule’ of the memory used by the model to get the highest efficiency. In other words, it generates the essential code needed to run a TinyNAS customized neural network – and is much more efficient than previous solutions to this problem that rely on less efficient and larger general-purpose inferencing engines.
The researchers say the application of TinyNAS and TinyEngine techniques within the MCUNet system have helped them outperform the previous state-of-the-art neural network and inference engine combo for image classification by more than 16 percent – a very significant leap for microcontroller settings. “The co-design of neural architecture and the inference engine opens the door for more optimization opportunities and eliminates redundancies,” says Han.
While the results are impressive, the work doesn’t stop there. The scientists are confident they can boost the performance of recognition tasks further, as well as putting them on even cheaper microcontrollers. “It’s a very promising start of the future ‘clever’ Internet of Things,” says Cohn, “to enable more efficient AI that requires less data, compute power and human resources.”
This post originally appeared on the IBM Research Blog.
Please cite our work using the BibTeX below.
@misc{lin2020mcunet,
title={MCUNet: Tiny Deep Learning on IoT Devices},
author={Ji Lin and Wei-Ming Chen and Yujun Lin and John Cohn and Chuang Gan and Song Han},
year={2020},
eprint={2007.10319},
archivePrefix={arXiv},
primaryClass={cs.CV}
}