SPAHM: Parameter matching for model fusion
Authors
Authors
- Mikhail Yurochkin
- Soumya Ghosh
- Kristjan Greenewald
- Nghia Hoang
- Mayank Agarwal
Authors
- Mikhail Yurochkin
- Soumya Ghosh
- Kristjan Greenewald
- Nghia Hoang
- Mayank Agarwal
Published on
12/10/2019
Categories
In this post, we share a brief Q&A with the authors of the paper, Statistical Model Aggregation via Parameter Matching, presented at NeurIPS 2019.
Statistical Model Aggregation via Parameter Matching
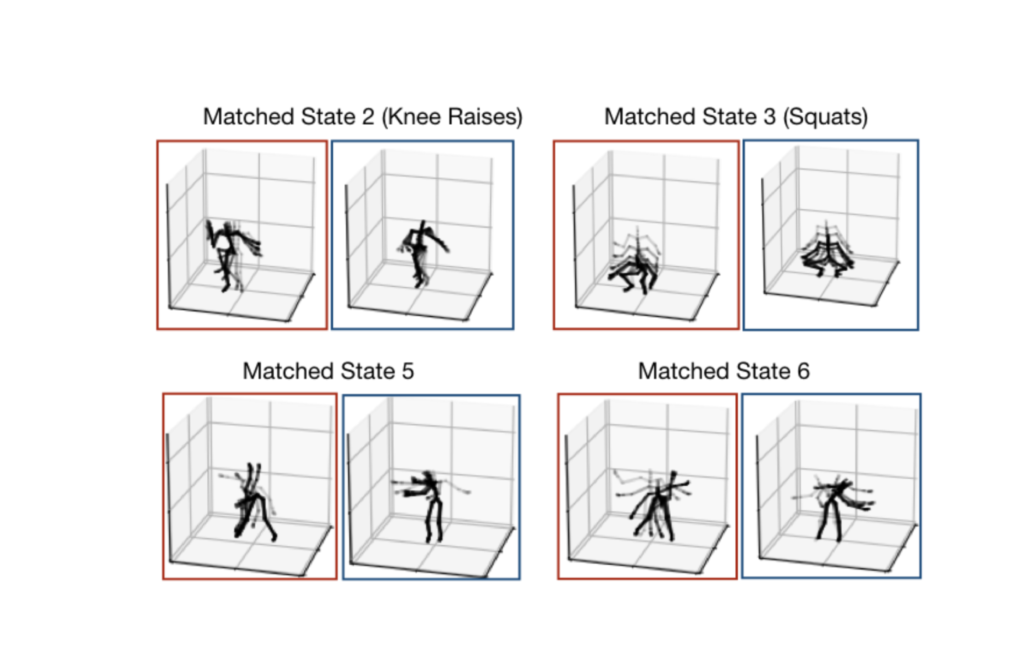
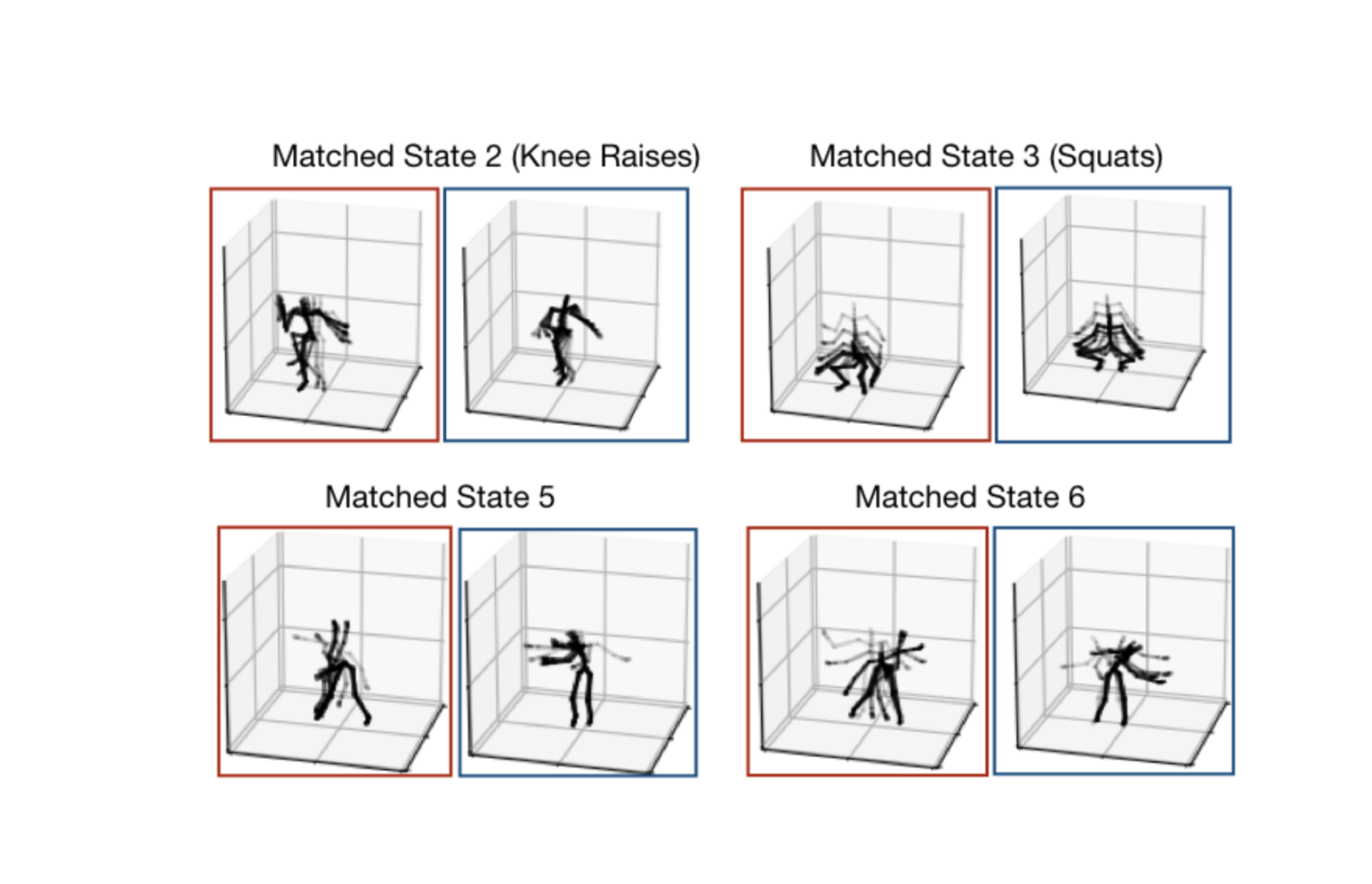
Abstract: We consider the problem of aggregating models learned from sequestered, possibly heterogeneous datasets. Exploiting tools from Bayesian nonparametrics, we develop a general meta-modeling framework that learns shared global latent structures by identifying correspondences among local model parameterizations. Our proposed framework is model-independent and is applicable to a wide range of model types. After verifying our approach on simulated data, we demonstrate its utility in aggregating, Gaussian topic models, hierarchical Dirichlet process based hidden Markov models, and sparse Gaussian processes with applications spanning text summarization, motion capture analysis, and temperature forecasting.
What is your paper about?
We consider the problem of model fusion — combining pre-trained machine learning models into a single model that improves upon the original models. We make minimal assumptions about the original models, which may have been trained from heterogeneous data, of varying quality, and potentially using different learning algorithms. We exploit tools from Bayesian nonparametrics to formalize this problem and offer an elegant solution applicable to a wide variety of popular statistical models.
What is new and significant about your paper?
Model fusion is an emerging technique motivated by (1) data privacy restrictions; (2) abundance of AI systems highly successful in handling a single data modality, but failing on heterogeneous and multi-modal data. Our SPAHM algorithm is an important step towards addressing these challenges.
What will the impact be on the real world?
Our algorithm can be applied in Federated Learning applications when parties do not have access to the original training data (for example, to comply with GDPR), but maintain pre-trained models. This can have a large impact on enterprises unwilling to share data with others but willing to share pre-trained legacy models. SPAHM is also a simple to use technique for distributed learning.
What would be the next steps?
In the future work we would like to extend SPAHM to fuse pre-trained posterior distributions rather than just parameters as is currently done. This would allow us to account for epistemic uncertainty, i.e., the uncertainty in model parameters. We are also interested in developing fusion techniques for deep neural network based models.
What surprised you the most about your findings?
There is an interesting mathematical finding: despite the complicated combinatorial structure exhibited by the model fusion objective, it can be reformulated as a linear sum assignment problem using what we call the subtraction trick. This reformulation allowed us to repurpose efficient algorithms for solving the assignment problem for model fusion.
What was the most challenging part of your research?
To show broad applicability of our model fusion techniques, we decided to show four applications using four different models: mixture models, topic models, Gaussian processes and hidden Markov models. It is possible that all of these models were never considered in a paper simultaneously before.
What made you most excited about this paper?
The generality of the method: the same fusion approach and indeed the same code works for a diverse collection of models and problems.
Please cite our work using the BibTeX below.
@misc{yurochkin2019statistical,
title={Statistical Model Aggregation via Parameter Matching},
author={Mikhail Yurochkin and Mayank Agarwal and Soumya Ghosh and Kristjan Greenewald and Trong Nghia Hoang},
year={2019},
eprint={1911.00218},
archivePrefix={arXiv},
primaryClass={stat.ML}
}